.svg)
TFHE-rs v0.8: Encrypted Arrays and Improved Multi-GPU Support
TFHE-rs v0.8 introduces array types and enhances multi-GPU computing. With this release, developers can now work with vectors and tensors more easily. In addition, the enhanced multi-GPU drastically reduces the computation time for arithmetic operations on GPUs. For instance, multiplying two encrypted 64-bit integers now takes about 100 ms on 8xH100, versus 366 ms on a high-end CPU, bringing a 3.5x speedup. This blog post will walk through an example using homomorphic arrays, and provide additional timing results. As usual, this release also introduces many new features, as described in the final section.
Computing on encrypted arrays
TFHE-rs v0.8 introduces n-dimensional arrays (or tensors) for encrypted data. This makes it easy to define vector or matrix homomorphic operations. The supported operations include:
- Element-wise Addition
- Element-wise Subtraction
- Element-wise Multiplication
- Element-wise Division
- Element-wise Remainder
- Element-wise BitAnd
- Element-wise BitOr
- Element-wise BitXor
The following example demonstrates some of the capabilities of the new array types: It shows how to extract submatrices of size 2x2 from two 4x4 matrices, perform addition, and then add a clear matrix to the previous results. You can find more details on how to use homomorphic arrays in the documentation.
Enhanced multi-GPU support
In TFHE-rs v0.7, multi-GPU support was introduced, leveraging NVLink to handle data sharing between GPUs. However, this feature was limited to platforms with NVLink, restricting its scalability. TFHE-rs v0.8 eliminates these limitations and offers the following improvements:
- All Nvidia GPUs, including the ones connected with PCIe, can now be used in the computations.
- NVLink connections between GPUs are used for memory transfers when available. Inter-GPU communication for integer multiplications has been optimized, improving scaling.
Thanks to optimizations in the Programmable Bootstrap and the Fast Fourier Transform CUDA implementations, single GPU performance has also been improved by approximately 20%.
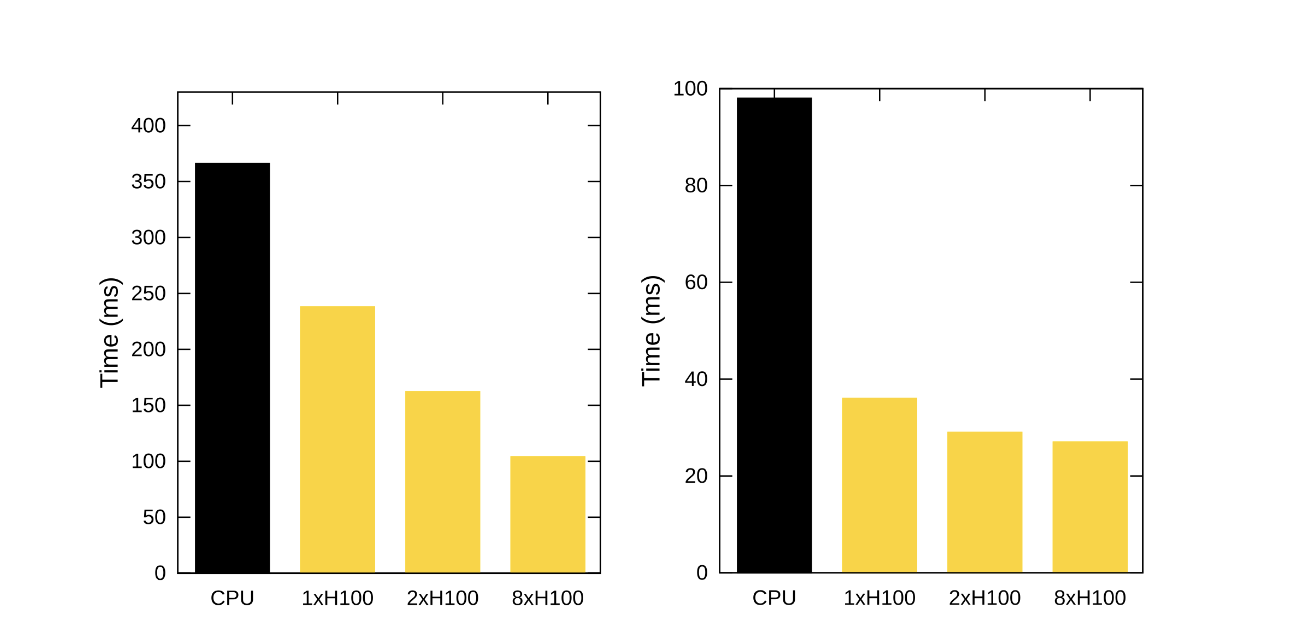
The optimal number of GPUs per operation varies depending on the operation itself and the integer precision specified by the user. Comprehensive arrays of benchmark results for both single and multiple GPUs across all specified precisions are available in the documentation.
Note that it is possible to select which GPUs to use for a computation on a multi-GPU platform, via the following environment variable:
This will limit computation to the GPUs specified, even if the system has more available. For example, here the GPUs 0, 1 and 2 are marked as visible on the platform, meaning that even if the platform has 8 GPUs, only those selected in [.c-inline-code]CUDA_SET_DEVICES[.c-inline-code] will be used for the computation. This can be useful to perform computations on different GPUs on the same machine.
Finally, note that it is no longer necessary to manually specify GPU specific parameters to get the best performance on GPU, they are automatically configured when calling:
Additional features and improvements
TFHE-rs v0.8 introduces several other features:
- Post homomorphic computation ciphertext compression on GPU: This reduces memory usage and enhances performance for larger workloads.
- More GPU-based homomorphic operations: New operations such as division between a scalar and an encrypted value, integer logarithm, and the trailing/leading zeros or ones are now available.
- Bootstrapping improvements: The bootstrapping on GPU has been improved by 22% on H100. Computing one bootstrapping on a 4-bits input now takes 3 ms. More complete benchmarks can be found in the GPU benchmarks documentation.
- CPU operation improvements: Some operations such as addition, subtraction, comparison have been improved on CPU. The latency has been reduced by 16% on the 64-bits multiplication. More details are available in the CPU benchmarks documentation.
- Parity detection: New operations that allow you to homomorphically determine the parity of integers are also available.
- Encrypted random FheBool: You can now generate random encrypted [.c-inline-code]FheBool[.c-inline-code] values.
With the release of TFHE-rs v0.8, the team has worked on improving the overall code stability, and added plenty of new features. Refer to the release note to see the full list. The next release of TFHE-rs will focus on introducing new data types and continuing to improve the overall performance. Stay tuned for the upcoming update!
Additional links
- Star the TFHE-rs Github repository to endorse our work and help us to reach the 1,000 stars ⭐️ milestone!
- Review the TFHE-rs documentation.
- Get support on our community channels.
- Participate in the Zama Bounty Program to get rewards in cash!
%20(1).jpg)

.png)